ViewModel是Google强推的Android开发最佳实践工具包Jetpack中的重要一员,用法比较简单,网上有许多介绍了其用法的文章,故此文不再介绍其用法。本文会从源码角度尝试解答ViewModel的几个相关问题:
ViewModel实例如何创建与存储
什么时候会清空数据,为何配置发生变化的销毁不会导致数据清空
ViewModel如何避免造成内存泄漏
AndroidViewModel怎么做到不会发生内存泄漏的
1. ViewModel实例如何创建与存储 一切得从获取ViewModel具体实例的方法开始说起。val viewModel = ViewModelProvider(this).get(TestViewModel::class.java) 为例说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class ViewModelProvider { private final Factory mFactory; private final ViewModelStore mViewModelStore; public ViewModelProvider(@NonNull ViewModelStoreOwner owner) { this (owner.getViewModelStore(), owner instanceof HasDefaultViewModelProviderFactory ? ((HasDefaultViewModelProviderFactory) owner).getDefaultViewModelProviderFactory() : NewInstanceFactory.getInstance()); } public ViewModelProvider(@NonNull ViewModelStore store, @NonNull Factory factory) { mFactory = factory; mViewModelStore = store; } }
Activity和Fragment都实现了ViewModelStoreOwner和HasDefaultViewModelProviderFactory接口,分别用于创建ViewModelStore实例和ViewModel实例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class ComponentActivity extends androidx .core .app .ComponentActivity implements ContextAware, LifecycleOwner, ViewModelStoreOwner, HasDefaultViewModelProviderFactory, SavedStateRegistryOwner, OnBackPressedDispatcherOwner, ActivityResultRegistryOwner, ActivityResultCaller public class Fragment implements ComponentCallbacks , OnCreateContextMenuListener , LifecycleOwner , ViewModelStoreOwner , HasDefaultViewModelProviderFactory , SavedStateRegistryOwner , ActivityResultCaller
在构造ViewModelProvider对象实例时,ViewModelProvider会通过ViewModelStoreOwner类型入参获取到ViewModel实例的创建者和存储者。接下来看看ViewModel实例是如何被创建及存储的。
1 2 3 4 5 6 7 8 public <T extends ViewModel> T get (@NonNull Class<T> modelClass) { String canonicalName = modelClass.getCanonicalName(); if (canonicalName == null ) { throw new IllegalArgumentException("Local and anonymous classes can not be ViewModels" ); } return get (DEFAULT_KEY + ":" + canonicalName, modelClass); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public <T extends ViewModel> T get (@NonNull String key, @NonNull Class<T> modelClass) { ViewModel viewModel = mViewModelStore.get (key); if (modelClass.isInstance(viewModel)) { if (mFactory instanceof OnRequeryFactory) { ((OnRequeryFactory) mFactory).onRequery(viewModel); } return (T) viewModel; } else { if (viewModel != null ) { } } if (mFactory instanceof KeyedFactory) { viewModel = ((KeyedFactory) mFactory).create(key, modelClass); } else { viewModel = mFactory.create(modelClass); } mViewModelStore.put(key, viewModel); return (T) viewModel; }
总结:在获取ViewModel的时候会先从ViewModelStore中的HashMap数据结构中读取实例,如果ViewModelStore中不存在该实例则通过反射方式创建实例并且存储到ViewModelStore中。
2. 什么时候会清空数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 protected void onCleared() { } @MainThread final void clear() { mCleared = true ; if (mBagOfTags != null ) { synchronized (mBagOfTags) { for (Object value : mBagOfTags.values()) { closeWithRuntimeException(value); } } } onCleared(); } public final void clear() { for (ViewModel vm : mMap.values()) { vm.clear(); } mMap.clear(); }
ViewModel数据清空即被调用onCleared方法,而ViewModel的onCleared方法只会在ViewModelStore#clear中会被调用,阅读源码发现ViewModelStore的clear只会发生在宿主Activity#onDestroy或Fragment被移除时:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 getLifecycle().addObserver(new LifecycleEventObserver() { @Override public void onStateChanged(@NonNull LifecycleOwner source, @NonNull Lifecycle.Event event) { if (event == Lifecycle.Event.ON_DESTROY) { mContextAwareHelper.clearAvailableContext(); if (!isChangingConfigurations()) { getViewModelStore().clear(); } } } });
总结:ViewModelStore中的map会在宿主Activity或Fragment销毁时被清理。
为何配置发生变化的销毁不会导致数据清空?
从上面注释的代码行中可以发现,只有是非配置变化导致的Activity#onDestroy才会触发ViewModelStore的clear方法。
但有个问题,我们知道尽管是配置变化引起的Activity销毁,但新建的Activity是一个全新的对象,那这个新Activity对象是如何继承前一个Activity中的ViewModel实例的呢?换句话说,或者是如何继承前一个Activity中的ViewModelStore实例的呢?
答案就在Activity的NonConfigurationInstances类型的mLastNonConfigurationInstances成员中。
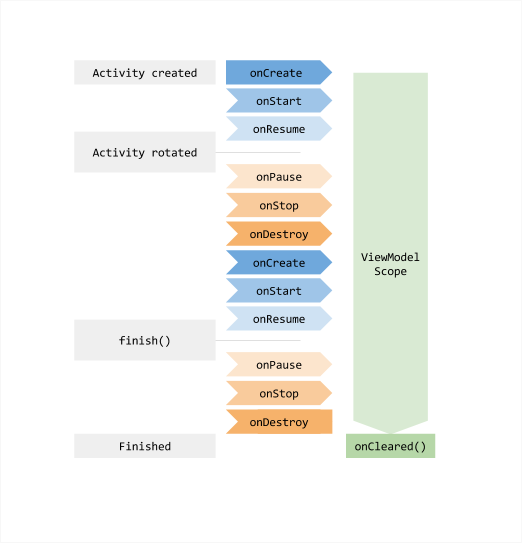
3. ViewModel如何避免造成内存泄漏 Google官方对于ViewModel生命周期与Activity生命周期的关系说明:
经分析,我们已经知道在ViewModel的宿主Activity或Fragment在被销毁时会调用ViewModel#clear,但假设我们在ViewModel中持有的宿主的引用,而又不在clear时释放引用,那此时便会造成内存泄漏。
一些避免ViewModel造成内存泄漏的建议和做法:
避免持有宿主的引用
在ViewModel#clear时释放宿主的引用、取消网络请求、关闭数据库连接,如:1 2 3 4 5 6 7 8 9 10 11 12 class MyViewModel : ViewModel () { private var activityRef: WeakReference<Activity>? = null fun setActivity (activity: Activity ) activityRef = WeakReference(activity) } fun clear () activityRef?.clear() activityRef = null } }
4. AndroidViewModel怎么做到不会发生内存泄漏的 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class AndroidViewModel extends ViewModel { @SuppressLint("StaticFieldLeak" ) private Application mApplication; public AndroidViewModel(@NonNull Application application) { mApplication = application; } @SuppressWarnings("TypeParameterUnusedInFormals" ) @NonNull public <T extends Application> T getApplication() { return (T) mApplication; } }
来看下AndroidViewModel的源码,AndroidViewModel是ViewModel的一个子类,它提供了一个Application对象的引用,通过在AndroidViewModel中使用Application Context而不是Activity或Fragment的Context来避免内存泄漏。这是因为Application Context的生命周期与应用程序的生命周期相同,而Activity的生命周期是短暂的,当Activity被销毁时,它的Context也会被销毁,如果在ViewModel中使用了Activity的Context,就可能会导致内存泄漏。